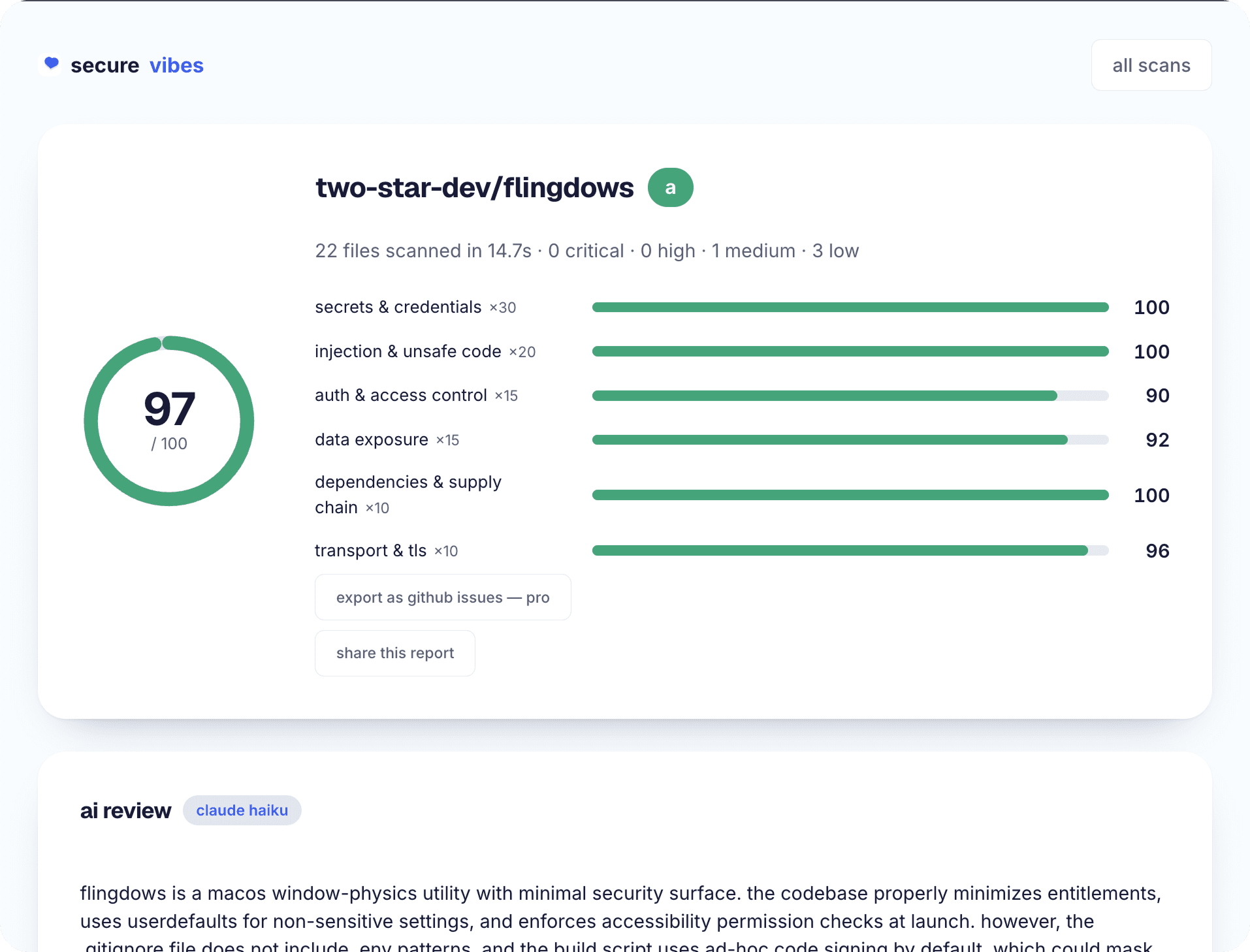
Six categories, weighted by consequence
Every repo is scored across six categories, and they don't count equally. Secrets & credentials carries weight 30 — almost a third of the total — because a committed live key is the most directly exploitable thing a repo can contain. Injection & unsafe code is 20. Auth & access control and data exposure are 15 each. Dependencies & supply chain and transport & TLS are 10 each.
The weighting is the opinionated part, and it's tuned to vibe-coded apps: the issues that are both most common in AI-generated codebases and most damaging when public get the most influence. A repo with perfect code but one committed Stripe key scores far worse than a repo with clean secrets and a missing lockfile — which matches how much trouble each will actually cause you.
How findings turn into a number
Each category starts at a perfect 100. Every finding in that category deducts points by severity: a critical finding costs 40, a high costs 22, a medium costs 10, a low costs 4. The deductions stack, so a category with one critical and two medium findings sits at 100 − 40 − 10 − 10 = 40. The overall score is then the weighted average of the six category scores.
Worked example: a critical secret finding (secrets category drops to 60) and one high injection finding (injection drops to 78), everything else clean. The overall score = (60×30 + 78×20 + 100×15 + 100×15 + 100×10 + 100×10) / 100 = 73.6 — a C. The math makes the priorities legible: fixing the secret recovers 12 weighted points on its own, which is precisely why it's ranked first in your findings list.
Grades, and what the score is not
The number maps to a letter: A at 90 or above, B at 80+, C at 65+, D at 50+, F below 50. An A means the scan found nothing serious; a C means real findings worth a fixing session; a D or F almost always means at least one critical issue — usually a committed secret — that should be handled today, starting with credential rotation.
Two honest boundaries. First, the score measures what pattern-based static checks can see: it doesn't execute your code, doesn't check dependencies against a CVE database, and isn't a pentest, so 100 means "clean against these checks", not "invulnerable". Second, it's most useful as a delta — scan, paste the fix prompts into Claude Code, re-scan, watch the grade move. The free monthly credits support exactly that fix-and-verify loop.
secure·vibes's scoring system at a glance
| Component | Value | Meaning |
|---|---|---|
| Secrets & credentials | weight 30 | Committed keys, hardcoded passwords, credentialed connection strings |
| Injection & unsafe code | weight 20 | String-built SQL, eval/exec, shell-from-variables, unsafe deserialisation |
| Auth & access control | weight 15 | Debug mode, wildcard CORS, default/none JWT secrets, cookie flags |
| Data exposure | weight 15 | Committed .env, key files, service-account JSON, dumps, .gitignore gaps |
| Dependencies & supply chain | weight 10 | Lockfiles, version pinning, raw-URL deps, curl|sh installs |
| Transport & TLS | weight 10 | Disabled TLS verification, plain-http calls, missing helmet on Express |
| Deductions per finding | crit −40 / high −22 / med −10 / low −4 | Stacking, from each category's starting 100 |
| Grades | A ≥90 · B ≥80 · C ≥65 · D ≥50 · F <50 | The overall score = weighted average of the six categories |
frequently asked
Why is one critical finding worth −40?
Because a critical finding — a live committed key, say — is not a 10% problem. The deduction is sized so a single critical drags its category to 60 and visibly dents the overall grade, which matches the real-world urgency of fixing it.
Can a category score go below zero?
Deductions stack per finding, so a category with many serious findings bottoms out — at that point the exact number matters less than the message: that whole category needs a dedicated fixing session, in the ranked order the report gives you.
Is a score of 100 a guarantee my app is secure?
No. It means the scan found nothing across its pattern-based checks — which is a genuinely good sign, but secure·vibes doesn't execute code, doesn't use a vulnerability database, and isn't a pentest. Treat 100 as a clean first pass, not a certificate.
How do I improve my score fastest?
Follow the ranked findings top-down — the ranking already accounts for severity and category weight. Fixing one critical secret recovers more weighted points than clearing every low finding in the report, and the per-finding Claude prompts make each fix a paste rather than a project.
Last updated June 10, 2026