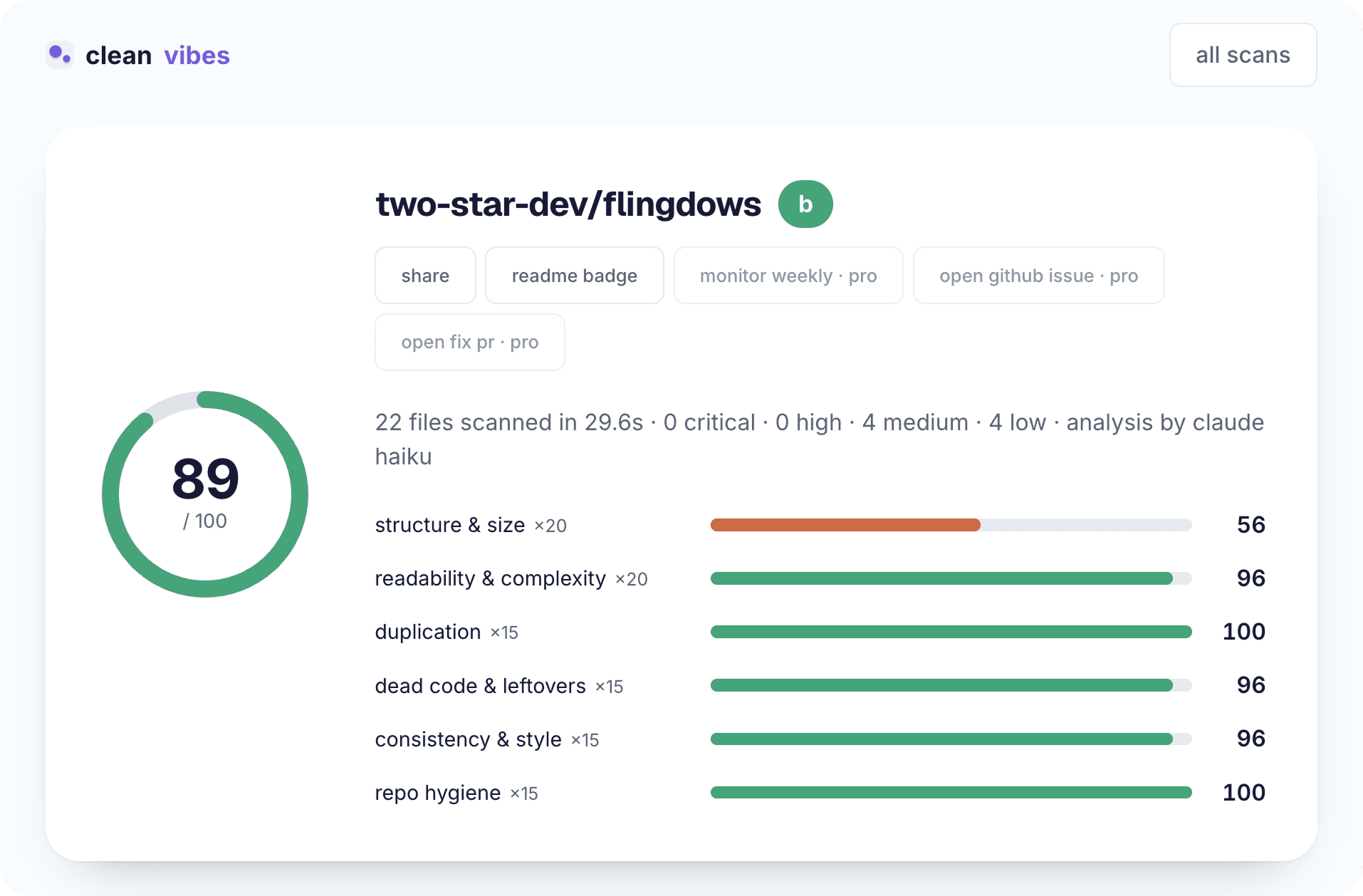
Six categories, weighted by how much the mess costs
Every repo is scored across six categories, and they don't count equally. Structure & size and readability & complexity carry weight 20 each — two-fifths of the total between them — because giant files and unreadable logic are what make a codebase slow and risky to change. Duplication, dead code & leftovers, consistency & style, and repo hygiene carry 15 each.
The weighting is the opinionated part, and it's tuned to vibe-coded apps: AI tools are happy to grow one file forever and to paste the same block four times, so the categories those habits land in get the most influence. A repo with tidy hygiene but one 2,000-line file holding the whole app scores worse than a repo with clean structure and a missing README — which matches how much trouble each will actually cause you.
How findings turn into a number
Each category starts at a perfect 100. Every finding in that category deducts points by severity: a critical finding costs 40, a high costs 22, a medium costs 10, a low costs 4. The deductions stack, so a category with one high and two medium findings sits at 100 − 22 − 10 − 10 = 58. The overall score is then the weighted average of the six category scores.
Worked example: a 1,500-line file (high — structure drops to 78) and two blocks of commented-out code (two mediums — dead code drops to 80), everything else clean. The overall score = (78×20 + 100×20 + 100×15 + 80×15 + 100×15 + 100×15) / 100 = 92.6 — still an A, but the report tells you exactly which two habits to break before they compound. The math makes the priorities legible: the findings list is ranked so the most points-recovering fixes sit at the top.
Grades, and what the score is not
The number maps to a letter: A at 90 or above, B at 80+, C at 65+, D at 50+, F below 50. An A means the scan found little worth flagging; a C means real mess worth a tidy-up session; a D or F usually means structural problems — giant files, heavy duplication, committed build artifacts — that make every future change slower than it should be.
Two honest boundaries. First, cleanliness is not correctness: clean·vibes doesn't execute your code or run your tests, so a 95 means the repo is tidy, not that it's bug-free. Second, the score is most useful as a delta — scan, paste the fix prompts into Claude Code, re-scan, watch the grade move. clean·vibes shows "since last scan" deltas on every report, and the free monthly credits support exactly that tidy-and-verify loop.
clean·vibes's scoring system at a glance
| Component | Value | Meaning |
|---|---|---|
| Structure & size | weight 20 | Giant files, flat folder trees, cluttered repo roots |
| Readability & complexity | weight 20 | Six-deep nesting, very long lines, logic nobody can hold in their head |
| Duplication | weight 15 | The same block pasted across files, repeats within one file |
| Dead code & leftovers | weight 15 | Commented-out code, TODO piles, console.logs left in |
| Consistency & style | weight 15 | Mixed indentation, competing filename conventions, two package managers |
| Repo hygiene | weight 15 | Committed node_modules, junk files, no README, no lockfile, no tests |
| Deductions per finding | crit −40 / high −22 / med −10 / low −4 | Stacking, from each category's starting 100 |
| Grades | A ≥90 · B ≥80 · C ≥65 · D ≥50 · F <50 | The overall score = weighted average of the six categories |
frequently asked
Why do structure and readability outweigh the others?
Because they're where the cost of mess compounds. A junk file is annoying once; a 1,800-line file taxes every single change anyone ever makes. The weights put the score's attention where your future time goes.
Can a category score go below zero?
Deductions stack per finding, so a category with many findings bottoms out at zero — at that point the exact number matters less than the message: that whole category needs a dedicated tidy-up session, in the ranked order the report gives you.
Is a score of 100 a guarantee my code is good?
No. It means the scan found nothing across its checks — which is a genuinely good sign, but clean·vibes measures cleanliness, not correctness. It doesn't run your code or your tests, and it can't judge whether your business logic is right. Treat 100 as a tidy repo, not a verified one.
How do I improve my score fastest?
Follow the ranked findings top-down — the ranking already accounts for severity and category weight. Splitting one giant file recovers more weighted points than deleting every stray console.log, and the per-finding Claude prompts make each fix a paste rather than a project.
Last updated June 10, 2026