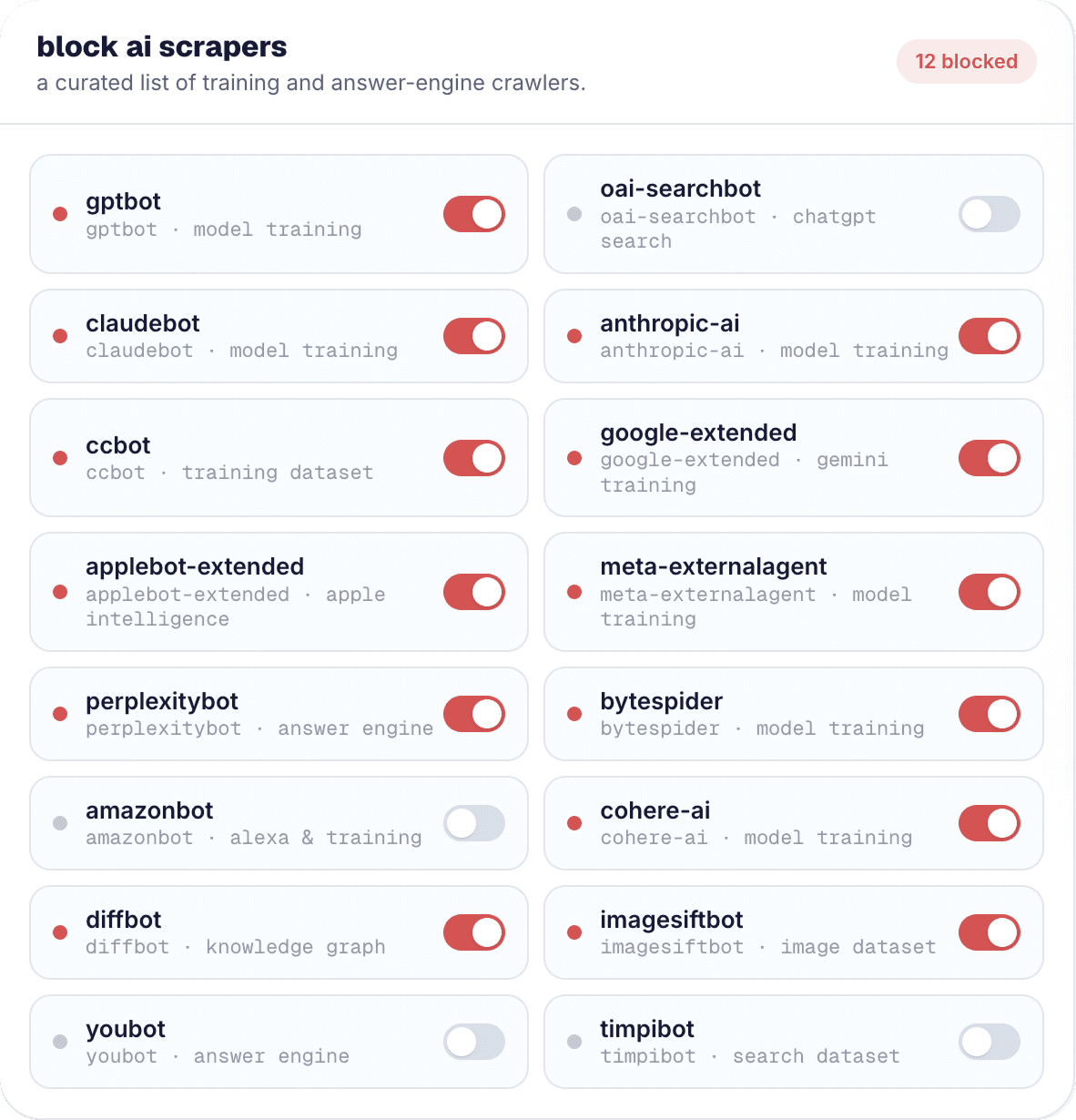
Grouped by operator: who runs what
OpenAI runs GPTBot for training data and OAI-SearchBot for its search and answer features. Anthropic runs ClaudeBot, with anthropic-ai also appearing in the wild as an associated token. Google uses Google-Extended as its dedicated AI-training opt-out token, separate from Googlebot. Common Crawl operates CCBot, whose archives feed a huge range of downstream AI training because so many models train on Common Crawl data.
Beyond those, Meta crawls with Meta-ExternalAgent, Apple uses Applebot-Extended as its AI-training control, Perplexity runs PerplexityBot for its answer engine, ByteDance operates Bytespider, and Amazon runs Amazonbot. Smaller but relevant operators include Cohere (cohere-ai), Diffbot, and ImagesiftBot. robot·guard ships all of these on a curated, maintained block list so you do not have to track each operator's announcements yourself.
Training, answer engines, and datasets are not the same
It helps to sort these by purpose. Training crawlers like GPTBot, Google-Extended, Applebot-Extended, and CCBot gather content to train or improve models. Answer-engine crawlers like OAI-SearchBot and PerplexityBot fetch pages to generate live answers and cite sources, which is closer to search than to training. Dataset crawlers like CCBot build public corpora that many other companies then train on, giving one block outsized reach.
The distinction matters because your goals might differ by category. You may be happy to appear in answer engines that cite and link you while refusing to be used as raw training material, or you may want to block both. Whitelisting the legitimate search crawlers (Googlebot, Bingbot, DuckDuckBot, the Internet Archive) while disallowing the AI training agents is a common, sensible split, and it is the default posture robot·guard is designed around.
Why a maintained list beats a copy-paste
A robots.txt snippet you copied from a blog post is frozen in time. The AI crawler landscape is not. New tokens appear, operators split training from search into separate agents, and casing or naming changes can quietly break a hand-edited rule. When that happens, your static file silently stops covering bots it was supposed to catch, and you have no way of knowing until you audit it.
A maintained tool solves this by keeping the curated list current and letting you preview the exact file before you publish. With robot·guard you toggle the operators you want to block, see the precise robots.txt output live, and download it, so your file stays aligned with the real-world list instead of drifting out of date. The free editor covers this; Pro adds accounts and cloud-synced configs if you manage multiple sites.
Common AI crawler user-agents in 2026, grouped by operator and purpose.
| user-agent | operator | purpose |
|---|---|---|
| GPTBot | OpenAI | AI model training |
| OAI-SearchBot | OpenAI | Search and answer engine |
| ClaudeBot | Anthropic | AI model training |
| Google-Extended | AI training opt-out token | |
| CCBot | Common Crawl | Public dataset that feeds many models |
| PerplexityBot | Perplexity | Answer engine fetching and citation |
| Meta-ExternalAgent | Meta | AI data collection |
| Applebot-Extended | Apple | AI training control token |
| Bytespider | ByteDance | AI data collection |
| Amazonbot | Amazon | Crawling and AI data collection |
frequently asked
What are the main AI crawler user-agents in 2026?
The ones to know include GPTBot and OAI-SearchBot (OpenAI), ClaudeBot and anthropic-ai (Anthropic), Google-Extended (Google), CCBot (Common Crawl), Meta-ExternalAgent (Meta), Applebot-Extended (Apple), PerplexityBot (Perplexity), Bytespider (ByteDance), and Amazonbot (Amazon), plus Cohere, Diffbot, and ImagesiftBot.
What is the difference between a training crawler and an answer-engine crawler?
Training crawlers like GPTBot, Google-Extended, and CCBot gather content to train models. Answer-engine crawlers like OAI-SearchBot and PerplexityBot fetch pages to generate live, cited answers, which is closer to search. You can choose to block one category and allow the other.
Why not just copy a robots.txt block list from a blog?
Because the list changes constantly. Operators add tokens, rename them, and split training from search. A copied snippet goes stale and silently stops covering new bots. A maintained, curated tool keeps the list current and lets you preview the exact file.
Does CCBot matter more than other crawlers?
It has outsized reach. Common Crawl builds a public dataset that many other companies train models on, so blocking CCBot can remove your content from numerous downstream training pipelines at once, not just one company's models.
Last updated June 9, 2026